The Internet, as we know it, has been slowly developed since the 1950’s. Originally designed by the Department of Defense and called ARPANET, it was meant to ensure communications through a wide variety of interconnected machines that could not be destroyed in the event of a nuclear attack. Now, over sixty years later, it serves up porn and endless Youtube videos, but I digress…
By its nature, the Internet was designed to be stateless. When a client such as a browser makes a request to a server, the client and server are only connected during the period of this, hopefully short, exchange. A user types in www.msn.com in their browser, the browser makes a request of the servers over at MSN, and MSN sends back a page full of HTML which is then displayed in the user’s browser. Immediately after this exchange, neither the browser nor the server has any knowledge of each other.
If a user just wanted to click on a single page, this would be fine. However, often times state matters. A lot. For example, if I was on Amazon’s page looking at hover boards suitable for an adorable nine year old girl with curly hair (it helps to be oddly specific), I can type hover board in the search bar. Amazon’s servers can send me a whole bunch of hover boards to look at, but my next request to Amazon’s server is going to need to let Amazon know which hover board I wanted to see.

When I click on any of the links above, the URL shown in my browser looks something like:
While the link itself is not very human readable, it is guiding the request to a certain script on Amazon’s server and passing in some parameters in the request’s querystring. When the server receives this request, based on the formation of the route and the querystring parameters, it knows which hover board should be displayed. State is maintained somewhat by generating URLs from the search request that have the right parameters in the querystrings to guide my next action. As a consequence of this, I can go to my browser and copy the URL and email it to my wife. She can bypass the search and go the exact hover board I was eyeing.
There are other mechanisms to maintain state. Sometimes web applications store data between requests on the client’s device by using a cookie or session. These objects cannot be easily seen by the end user. When a user logs into a site like Amazon, it is common practice to return back a token which will act as the user’s name and password for subsequent requests. The token is stored on the client, but never exposed in the URL. Most of the time, the token is used in future requests by placing it as an authorization header. While the token can be found by advanced users, it prevents the password from being cached on the local machine. It is also never placed directly in the URL so that it cannot be accidentally sent to another user who could then log in as an authenticated user and make unauthorized purchases.
The point here being is that some things belong in the URL, some things clearly do not. From Amazon’s perspective, me copying and pasting a product page is a good thing. More eyeballs means more sales. In the olden day, each URL corresponded to a specific script that would be executed. The HTML that was dynamically generated and returned back to the user would be routed correctly by the web application. However, more modern web architecture, when done correctly, usually utilizes a Single Page App (SPA).
A SPA contains all the magical javascript libraries, css sheets, and static text the user will ever need. The portions that are generated dynamically still go through the same request/response series as before, but now the exchange is much lighter with a few bytes of JSON objects going back and forth instead of resending all of the CSS, HTML, Javascript, etc. needed to render a page.
Clicking on links within a SPA often times changes the URL in the browser. Although there is no flicker as the page changes, an internal router may reach out to the query string in the URL to know which product to render if the example above were written in a SPA (it’s not). Having the URL change even though the page is not truly reloading has the advantage that a user can send a link to another user and have them land in the exact same location.
I have written a few SPAs recently and hosted them on Amazon Web Service’s (AWS) S3 service. S3 allows for highly scalable, highly available objects to be stored. With a minor configuration change, S3 can host a static website. The best part is, as of this writing, it costs about 2.4 cents per gigabyte per month to host content there. Since my SPA needed a place to live where I could access it from anywhere and 2.4 cents a month seemed like a reasonable enough price to pay, that’s where I put it.
Except, there was one hitch… Serving up the index page worked like a charm. But if there was anything after the index page, it would trigger an error. Pressed with other things, I didn’t dig too far into it at the time, but I realized what was happening. Having anything off the base URL was having S3 make a request to an object that did not exist. My SPA made use of the querystring and expected to route things internally. Clicking on the base URL and clicking around in the app worked fine. Refreshing the browser or sending a link to someone else failed.
Fortunately, I am not the first person to do this. I probably will not be the last. There is an easy solution that is available. While you can use any domain registrar and utilize AWS resources, I would recommend using the AWS Route 53 service. It makes life a lot easier and costs roughly the same as the others.
For the domain you want to forward to your static website, log into your AWS account. Make sure that your geography is set to N. Virginia (us-east-1). There is a weird quirk about Amazon Certificate Manager (ACM) in that it only works in us-east-1. Regardless of which region your other infrastructure will reside, using ACM set to us-east-1 will still work. Go to ACM.
Click Request a certificate. Provide the base URL the user will put in their browser. Click Next.

On the next screen, if you have the domain registered to you, it is probably easier to use email validation. I have been using email validation and receiving the email in a few seconds. After approving the email, the certificate is issued and it is on to the next step…
From the AWS Console, select CloudFront. CloudFront is an Amazon service that enables caching of static (or in most people’s case, near static) assets at “edge locations”. Most of my static content is stored somewhere in Oregon, but I currently (but not for long!) live in Texas. When I make a request to my static content located in Oregon, it has to go through several hops that cost precious milliseconds and degrade the overall performance of my site. By caching my content at locations throughout the United States, my request goes through fewer hops making the initial request much faster. Remember, in web development, every millisecond counts!
Create a new distribution by clicking the “Create Distribution” button. Select a Web distribution by clicking “Get Started” in that section.

For the Origin Domain Name, select the bucket that is hosting your static content. A drop down should appear listing your buckets when you click on it. Under Viewer Protocol Policy, I like to select Redirect HTTP to HTTPS. Most browsers will not allow a page served over HTTP to make calls to APIs using HTTPS. By selecting the redirect to HTTPS, any user who does not specifically type https://www.yourwebsite.com will automatically be pushed to the HTTPS version of it. This is seamless to the user and will allow the website to function properly when combined with APIs which probably should be communicating over HTTPS.
Under distribution Settings, make sure to provide the Alternate Domain Name that you just requested a certificate via ACM. Select the radio button for Custom SSL Certificate and find the newly created cert. For Price Class, take a look at the options. If you are in the US and do not anticipate taking Asia by storm, it might make sense to choose another option instead of the default All Edge Locations. Your mileage may vary.
It may take several minutes for the CloudFront distribution to be ready. Once it is, you will want to click on the “Error Pages” tab from the distribution. Also, take note of the Domain Name, in this case d209zgrmi...cloudfront.net. Asking users to remember that is an exercise in futility, so we will go to Route 53 and make sure our custom domain name goes to this distribution.

On the Error Pages, tab create two entries. You will want 403’s and 404’s to redirect to your /index.html with 0 error caching and return a 200 response code:

Now go to Route 53. Click “Hosted zones” on the left hand nav. Click the domain name you have registered and create two record sets. One will be an A record for ipv4 and one will be an AAAA record for ipv6. Both will look like this:
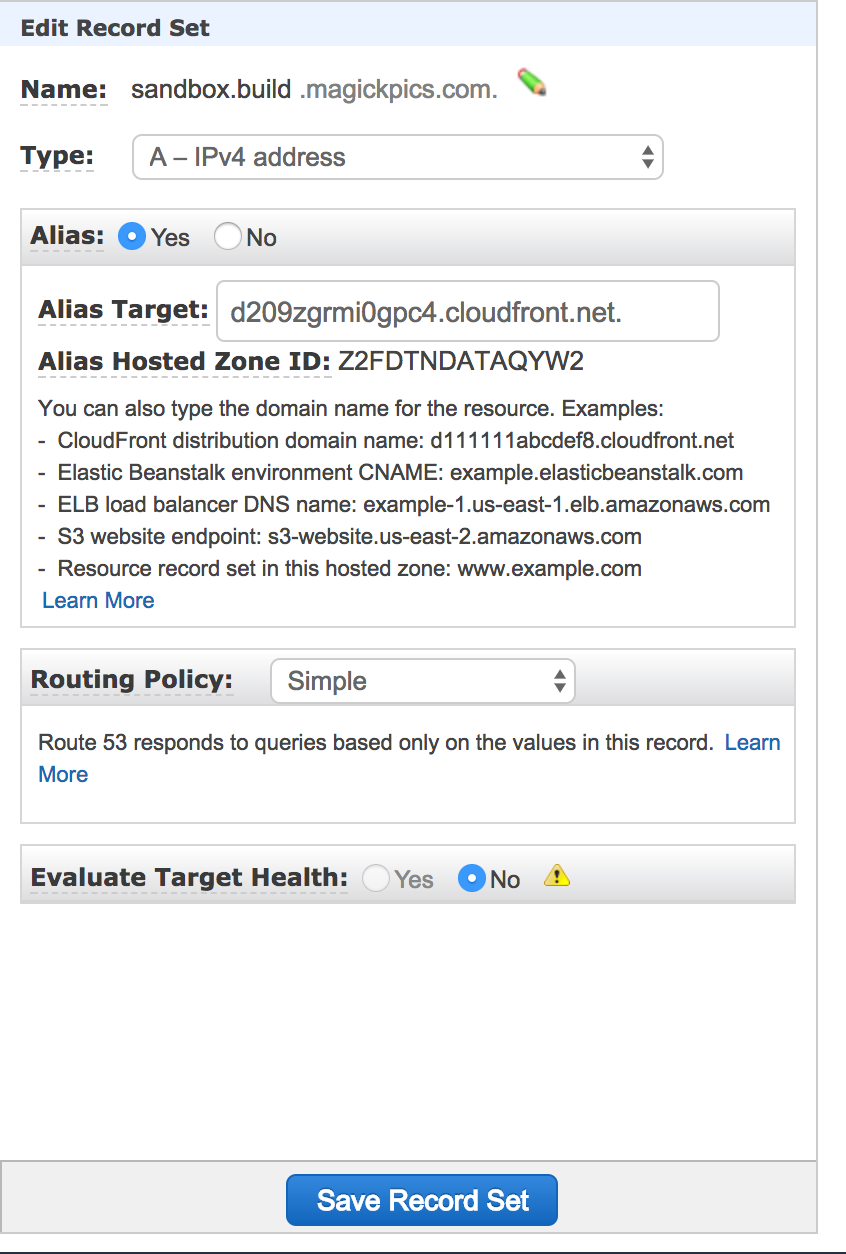
Set the Alias Target to the domain provided by your CloudFront distribution and save the record sets. It may take a few minutes to propagate, but shortly your users can type in your URL and be taken to the SPA hosted on S3 and cached throughout the country at edge locations. If the user refreshes the page when they are not on the root URL, instead of getting an error, the SPAs internal router will handle perform as expected. Additionally, users can copy and paste the URL and distribute non-sensitive information because we are smart enough to know not to put tokens or secure data in the querystring :) Recipients of the URL will be able to load the SPA and be taken to the appropriate page.
One last note, if there is a change made to the content of the SPA in S3, it can take up to 24 hours to propagate to all CloudFront edge locations. If you are making a critical UI change and don’t want your users to have to wait a day to see it, do not worry. After making the change and modifying the contents of your S3 bucket, go back to CloudFront and click on your distribution. You will see a tab labeled “Invalidations”. Click that tab! Click “Create Invalidation” and for the Object Paths, you can click /*. Once you have invalidated all objects in the cache, your users will see your changes on their next refresh. While invalidations are not free, each account gets 3,000 per day free of charge, plan accordingly.





